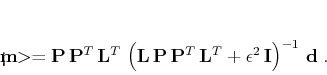|
|
|
|
Multidimensional recursive filter preconditioning in geophysical estimation problems |
The data-space regularization approach is closely connected with the
concept of model preconditioning.
We can introduce a new model ![]() with
the equality
with
the equality
Equation (11) is clearly underdetermined with respect to
the compound model
![]() . If from all possible solutions of
this system we seek the one with the minimal power
. If from all possible solutions of
this system we seek the one with the minimal power
![]() , the formal result takes the well-known form
, the formal result takes the well-known form
To prove the equivalence, consider the operator
This proves the legitimacy
of the alternative data-space approach to data regularization: the
model estimation is reduced to a least-squares minimization of the
specially constructed compound model
![]() under the
constraint (9).
under the
constraint (9).
We summarize the differences between the model-space and data-space regularization in Table 1.
| Model-space | Data-space | |
| effective model |
![$\hat{\mathbf{p}} =
\left[\begin{array}{c} \mathbf{p} \mathbf{r} \end{array}\right]$](img37.png) |
|
| effective data |
![$\hat{\mathbf{d}} =
\left[\begin{array}{c} \mathbf{d} \mathbf{0}
\end{array}\right]$](img38.png) |
|
| effective operator |
![$\mathbf{G_m} = \left[\begin{array}{c} \mathbf{L} \\
\epsilon \mathbf{D} \end{array}\right]$](img39.png) |
|
| optimization problem | minimize
where |
minimize
under the constraint |
| formal estimate for |
where |
where |
Although the two approaches lead to similar theoretical results, they behave quite differently in the process of iterative optimization. In the next section, we illustrate this fact with many examples and show that in the case of incomplete optimization, the second (preconditioning) approach is generally preferable.
|
|
|
|
Multidimensional recursive filter preconditioning in geophysical estimation problems |
![\begin{displaymath}
\hat{\mathbf{p}} = \left[\begin{array}{c} \mathbf{p} \mathbf{r} \end{array}\right]\;.
\end{displaymath}](img24.png)
![\begin{displaymath}
\left[\begin{array}{cc} \mathbf{L P} & \epsilon \mathbf{I} ...
...array}\right] =
\mathbf{G_d} \hat{\mathbf{p}} = \mathbf{d}\;,
\end{displaymath}](img25.png)
![\begin{displaymath}
<\!\!\hat{\mathbf{p}}\!\!> = \left[\begin{array}{c}
<\!\!\m...
...lon^2 \mathbf{I}\right)^{-1} \mathbf{d}
\end{array} \right]\;.
\end{displaymath}](img30.png)