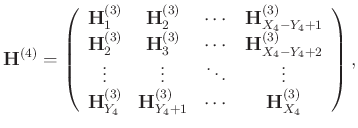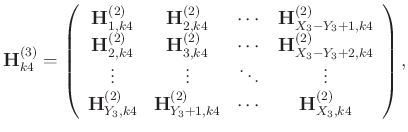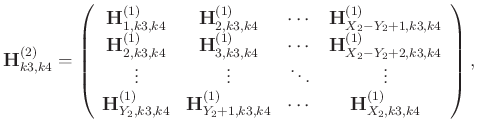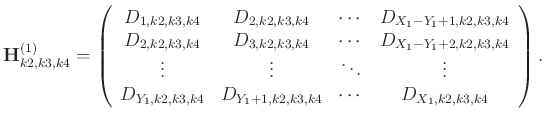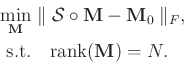|
|
|
|
Five-dimensional seismic data reconstruction using the optimally damped rank-reduction method |
Next: Optimal weighting for rank Up: Theory Previous: Theory
|
|
|
|
Five-dimensional seismic data reconstruction using the optimally damped rank-reduction method |
The level-four block Hankel matrix has the following explicit expression:
In order to make all target matrices (from equation 1 to 4) close to square matrices, parameters ![]() are defined as
are defined as
![]() ,
, ![]() , where
, where ![]() denotes the size of the
denotes the size of the ![]() th dimension. Here,
th dimension. Here,
![]() denotes the integer part of an input argument.
denotes the integer part of an input argument.
The process of transforming a four-dimensional hypercube
![]() to the block Hankel matrix
to the block Hankel matrix
![]() is referred to as the Hankelization process. We can briefly denote this process as:
is referred to as the Hankelization process. We can briefly denote this process as:
Another important step in the rank-reduction based method is the rank reduction process, which can be denoted as
![]() .
.
Reconstructing the missing data aims at solving the following equation:
Equation 6 is seriously ill-posed and the low-rank assumption is applied to constrain the model,
The problem expressed in equation 7 can be solved via the following iterative solver:
|
|
|
|
Five-dimensional seismic data reconstruction using the optimally damped rank-reduction method |